Brief Summary
Okay ji, so this video breaks down the attention mechanism in transformers, which are like, the heart of large language models. It explains how these models process text, refine word meanings based on context, and use multiple "attention heads" to capture different relationships between words. The video also touches upon masking, context size, and parameter counting in GPT-3. Basically, it's all about how machines understand the meaning behind words in a sentence.
- Attention mechanism refines word meanings based on context.
- Multiple "attention heads" capture different relationships between words.
- Masking prevents future words from influencing past words during training.
Recap on Embeddings
So, last time, we were looking at how transformers work, right? These are super important for big language models and other AI tools. This video, we're gonna go deeper into the attention mechanism, which is key. Remember, the model takes text, breaks it into tokens (usually words), and then turns each token into a high-dimensional vector called an embedding. The main thing to remember is that directions in this embedding space show semantic meaning, like how a certain direction can change a masculine noun to a feminine one. Transformers adjust these embeddings to add richer, contextual meaning to the words.
Motivating Examples
The attention mechanism can be confusing, so let's look at some examples first. Take the word "mole" in "American shrew mole," "one mole of carbon dioxide," and "take a biopsy of the mole." We know the meaning changes based on the context. But initially, the embedding for "mole" is the same in all cases. The transformer's next step lets surrounding embeddings give information to this one. Think of it like the embedding space having different directions for each meaning of "mole." The attention block figures out what to add to the generic embedding to move it to the right direction based on the context.
The Attention Pattern
Let's say our input is "a fluffy blue creature roamed the verdant forest." We want adjectives to adjust the meaning of nouns. This is a single "head" of attention. Each word's initial embedding encodes the word's meaning and position. We want computations to produce refined embeddings where nouns have taken in meaning from their adjectives. Nouns ask, "Are there any adjectives before me?" and adjectives answer, "Yes, I'm an adjective in that position." This question is encoded as a "query" vector. This query is computed by multiplying the embedding by a matrix (wq).
Masking
During training, the model predicts the next token for every subsequence of tokens. This means we don't want later words to influence earlier ones, as it could give away the answer. So, we force those spots in the attention pattern to be zero. We can't just set them to zero because the columns need to add up to one. Instead, we set those entries to negative infinity before applying softmax. After softmax, they become zero, and the columns stay normalized. This is called masking.
Context Size
The size of the attention pattern is the square of the context size. This is why context size is a bottleneck for large language models. Recent variations of the attention mechanism aim to make context more scalable, but we're focusing on the basics here.
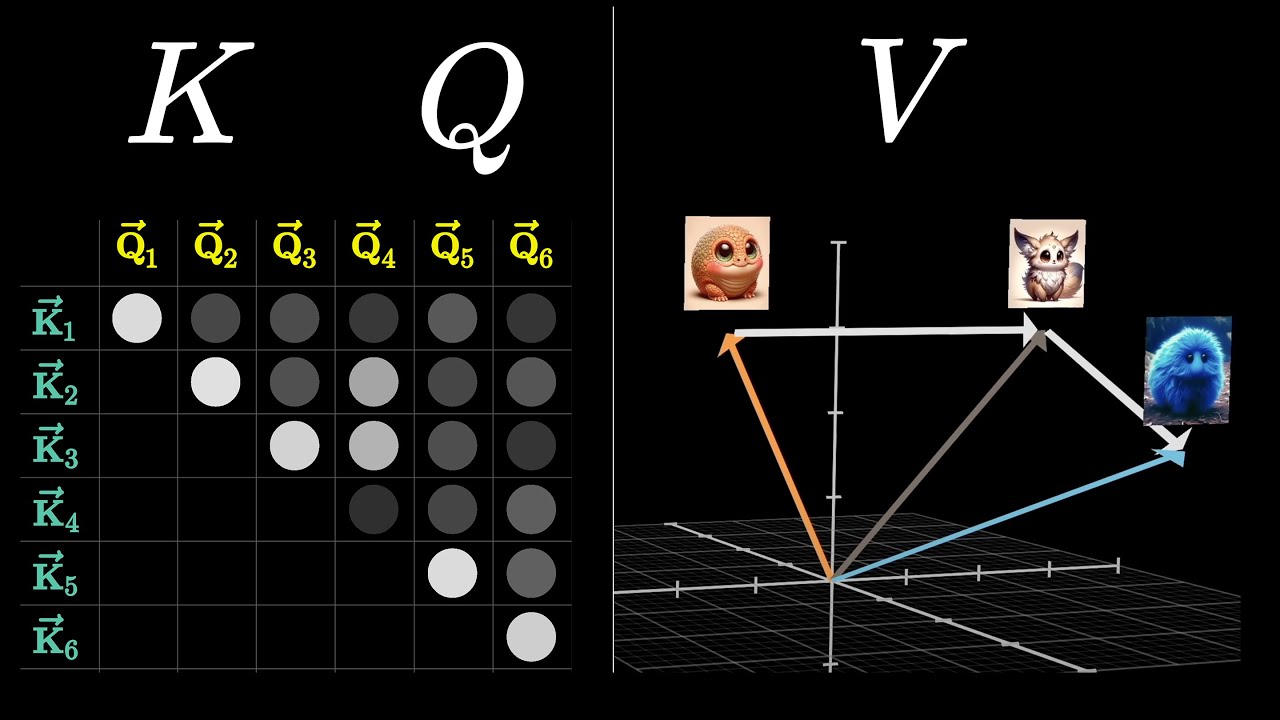
Values
Now that we have the attention pattern, we can update the embeddings. We want "fluffy" to change "creature" to encode "fluffy creature." We use a third matrix, the "value" matrix, which we multiply by the embedding of "fluffy." This gives us a "value vector," which we add to the embedding of "creature." The value matrix says, "If this word is relevant, what should be added to the other word's embedding?" We multiply each value vector by the corresponding weight in the attention pattern column. Then, we add together all the rescaled values in the column to produce a change (delta-e), which we add to the original embedding.
Counting Parameters
This whole process is a single "head" of attention, parameterized by the key, query, and value matrices. Let's count the parameters like we did last time, using GPT-3 numbers. The key and query matrices each have 12,288 columns (embedding dimension) and 128 rows (key-query space dimension), giving us about 1.5 million parameters each. The value matrix could be a square matrix with 12,288 rows and columns, meaning 150 million parameters. But it's more efficient to make the value map have the same number of parameters as the key and query matrices.
Cross-attention
Everything we've described so far is a self-attention head, to distinguish it from cross-attention. Cross-attention is used in models that process two distinct types of data, like text in two languages for translation. The key and query maps act on different datasets. In translation, keys might come from one language, while queries come from another. The attention pattern describes which words from one language correspond to which words in another. There's typically no masking in this setting.
Multiple Heads
We do this attention process many times. There are many ways context can influence a word's meaning. The key and query matrices would be different for each type of contextual updating, and the value map parameters would also be different. A full attention block consists of multi-headed attention, where we run many of these operations in parallel. GPT-3 uses 96 attention heads in each block. This means 96 distinct key and query matrices produce 96 distinct attention patterns. Each head has its own value matrices.
The Output Matrix
The value map is factored into two matrices: the value down and value up matrices. The value up matrices for each head are stapled together in one giant matrix called the output matrix, associated with the entire multi-headed attention block. When people refer to the value matrix for a given attention head, they're usually only referring to the value down projection.
Going Deeper
Data flows through a transformer through attention blocks and multi-layer perceptrons repeatedly. After a word takes in some context, there are more chances for this nuanced embedding to be influenced by its surroundings. The further down the network you go, the more the embeddings encode higher-level ideas like sentiment, tone, and underlying scientific truths.
Ending
GPT-3 has 96 layers, so the total number of key, query, and value parameters is multiplied by 96, bringing the total to just under 58 billion parameters devoted to attention heads. This is only about a third of the 175 billion parameters in the network. The attention mechanism is successful because it's extremely parallelizable, meaning we can run many computations quickly using GPUs. Scale alone gives huge improvements in model performance, so parallelizable architectures are a big advantage.

